 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCamera Pose Revisited
Jan 18, 2026Estimating the position and orientation of a camera with respect to an observed scene is one of the central problems in computer vision, particularly in the context of camera calibration and multi-sensor systems. This paper addresses the planar Perspective--$n$--Point problem, with special emphasis on the initial estimation of the pose of a calibration object. As a solution, we propose the \texttt{PnP-ProCay78} algorithm, which combines the classical quadratic formulation of the reconstruction error with a Cayley parameterization of rotations and least-squares optimization. The key component of the method is a deterministic selection of starting points based on an analysis of the reconstruction error for two canonical vectors, allowing costly solution-space search procedures to be avoided. Experimental validation is performed using data acquired also from high-resolution RGB cameras and very low-resolution thermal cameras in an integrated RGB--IR setup. The results demonstrate that the proposed algorithm achieves practically the same projection accuracy as optimal \texttt{SQPnP} and slightly higher than \texttt{IPPE}, both prominent \texttt{PnP-OpenCV} procedures. However, \texttt{PnP-ProCay78} maintains a significantly simpler algorithmic structure. Moreover, the analysis of optimization trajectories in Cayley space provides an intuitive insight into the convergence process, making the method attractive also from a didactic perspective. Unlike existing PnP solvers, the proposed \texttt{PnP-ProCay78} algorithm combines projection error minimization with an analytically eliminated reconstruction-error surrogate for translation, yielding a hybrid cost formulation that is both geometrically transparent and computationally efficient.
Multi-modal Residual Perceptron Network for Audio-Video Emotion Recognition
Jul 30, 2021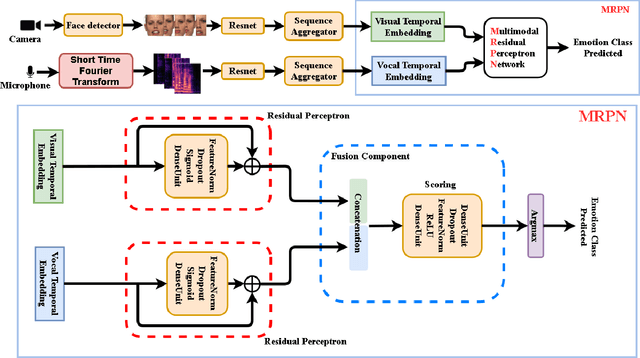
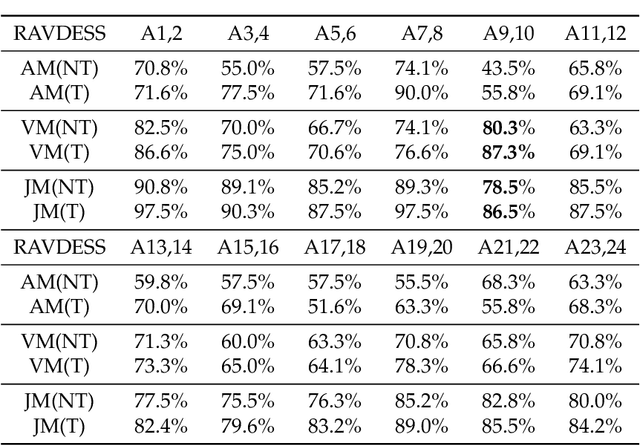

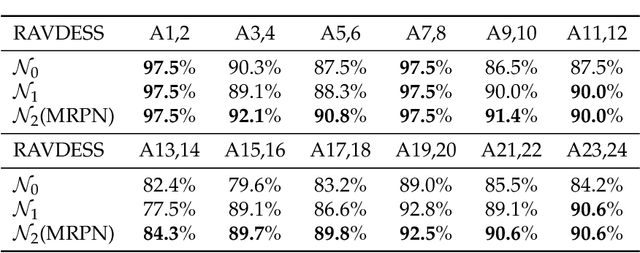
Audio-Video Emotion Recognition is now attacked with Deep Neural Network modeling tools. In published papers, as a rule, the authors show only cases of the superiority in multi-modality over audio-only or video-only modality. However, there are cases superiority in uni-modality can be found. In our research, we hypothesize that for fuzzy categories of emotional events, the within-modal and inter-modal noisy information represented indirectly in the parameters of the modeling neural network impedes better performance in the existing late fusion and end-to-end multi-modal network training strategies. To take advantage and overcome the deficiencies in both solutions, we define a Multi-modal Residual Perceptron Network which performs end-to-end learning from multi-modal network branches, generalizing better multi-modal feature representation. For the proposed Multi-modal Residual Perceptron Network and the novel time augmentation for streaming digital movies, the state-of-art average recognition rate was improved to 91.4% for The Ryerson Audio-Visual Database of Emotional Speech and Song dataset and to 83.15% for Crowd-sourced Emotional multi-modal Actors dataset. Moreover, the Multi-modal Residual Perceptron Network concept shows its potential for multi-modal applications dealing with signal sources not only of optical and acoustical types.